Stochastic gradient descent
Deep learning, Machine learning, Artificial neural network
An efficient and stochastic version of Gradient descent. An essential ingredient of Deep learning. Instead of computing the gradient of the loss function for the whole dataset, SGD creates small batches and perform many gradient descent sessions by rotating through the batches.
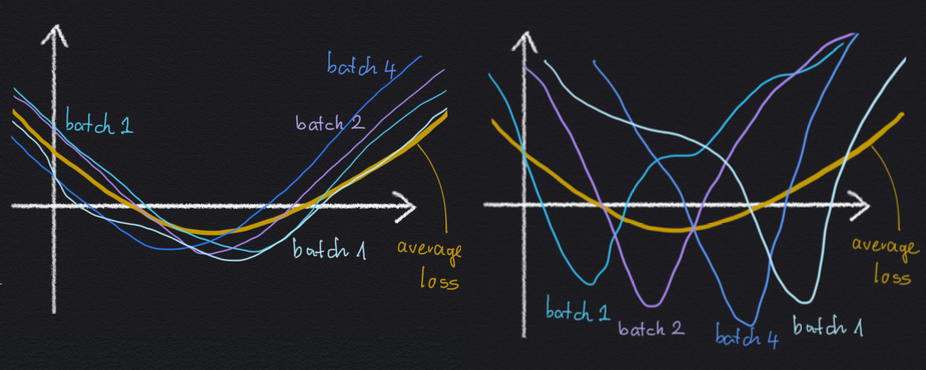
Smith2021origin argues that SGD provides implicit Regularization (see Barrett2021implicit regarding Gradient descent). Here is a note on these papers by Ferenc Huszár. An intuitive argument would be the following figure. Even if there are two similar-looking loss minima, the one where batches agree with each other is preferred in SGD, which is also the one that generalizes better.